


Quem já trabalhou com PySpark sabe como é frustrante quando uma aplicação trava por falta de memória. Você está lá, processando dados tranquilamente, quando de repente tudo para e aparece aquela mensagem de erro que ninguém quer ver. Acontece que o gerenciamento de memória no PySpark pode reduzir o consumo de recursos em até 2 vezes quando você sabe o que está fazendo.
Até pouco tempo atrás, descobrir onde estava o problema de memória nas aplicações PySpark distribuídas era como procurar agulha no palheiro, especialmente quando o problema estava nos executores Spark. Você ficava tentando adivinhar qual parte do código estava consumindo toda a memória disponível.
Felizmente, desde o Databricks Runtime 12.0, essa dor de cabeça diminuiu bastante com a chegada de ferramentas de análise de memória diretamente nos executores.
Hoje nós temos acesso a ferramentas de perfilamento de memória que mostram exatamente quais linhas de código nas suas UDFs estão devorando os recursos. Isso muda completamente a forma como conseguimos fazer as melhorias necessárias.
Existe também o Adaptive Query Execution, conhecido como AQE, que veio com o Spark 3.x e ajuda a melhorar os planos de execução das consultas enquanto elas estão rodando, usando as estatísticas que ele vai coletando.
A pergunta que fica é: como usar essas ferramentas de forma prática para melhorar o desempenho dos nossos notebooks no Databricks?
Vamos ver como organizar melhor o layout dos dados, como gerenciar os shuffles sem quebrar tudo, como resolver aqueles problemas chatos de skew e como usar cache de uma forma que realmente faça diferença no desempenho das suas aplicações.
Organizar os Dados e Escrever Melhor nas Tabelas Delta
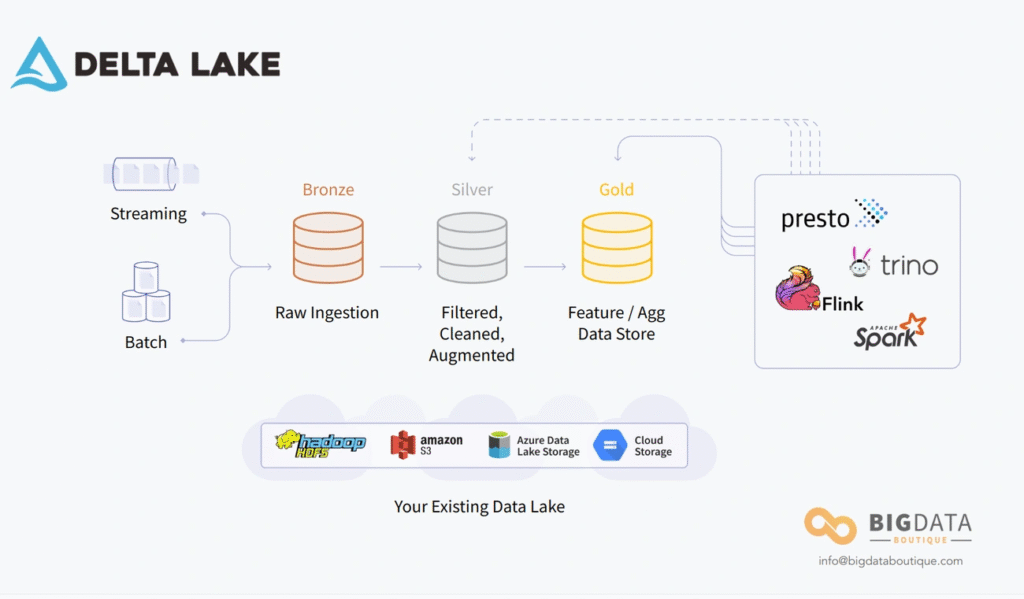
Você já deve ter passado por aquela situação onde uma consulta que deveria ser rápida acaba demorando uma eternidade. Muitas vezes o culpado são os “pequenos arquivos” no Delta Lake. Quando você está escrevendo dados com frequência, especialmente em streams ou atualizações em lote, acabam surgindo milhares de arquivos pequenos que criam uma bagunça nos metadados e fazem suas consultas ficarem lentas.
Felizmente, o Databricks tem algumas funcionalidades bem úteis para resolver essa questão de layout de dados em tabelas Delta.
delta.autoOptimize.optimizeWrite e delta.autoOptimize.autoCompact
Existe uma funcionalidade chamada optimizeWrite que diminui o número de arquivos escritos, fazendo com que cada arquivo fique maior durante as operações de escrita. A ideia é simples: ela pega várias escritas pequenas na mesma partição e junta tudo em uma operação só antes de executar, criando arquivos maiores e mais eficientes.
Para ativar essa funcionalidade, você tem duas opções:
- No nível da tabela:
delta.autoOptimize.optimizeWrite = true - No nível da sessão:
spark.databricks.delta.optimizeWrite.enabled = true
O autoCompact funciona como um complemento, executando automaticamente um pequeno comando optimize depois de cada operação de escrita. Basicamente, ele pega dados de arquivos que estão abaixo de um certo tamanho e junta em um arquivo maior, isso acontece logo depois que a escrita termina com sucesso.
Configuração delta.targetFileSize para controle de tamanho de arquivos
Para ajustar o tamanho dos arquivos nas suas tabelas Delta, você pode configurar a propriedade delta.targetFileSize com o tamanho que faz mais sentido. Uma vez que você define essa propriedade, todas as operações de otimização de layout vão fazer o possível para gerar arquivos do tamanho especificado.
O próprio Databricks já ajusta automaticamente o tamanho do arquivo baseado no tamanho da tabela:
- Para tabelas menores que 2,56 TB: 256 MB
- Para tabelas entre 2,56 TB e 10 TB: vai crescendo de forma linear de 256 MB até 1 GB
- Para tabelas maiores que 10 TB: 1 GB
Usar ZORDER para deixar dados relacionados no mesmo lugar
Z-Ordering é uma técnica interessante que coloca informações relacionadas no mesmo conjunto de arquivos. Essa organização é usada automaticamente pelos algoritmos de data-skipping do Delta Lake, o que diminui drasticamente a quantidade de dados que precisam ser lidos durante as consultas.
Para aplicar Z-Ordering, você especifica as colunas no comando OPTIMIZE:
OPTIMIZE events WHERE date >= current_timestamp() - INTERVAL 1 day ZORDER BY (eventType)Essa técnica funciona muito bem para colunas que você usa frequentemente em filtros e que têm alta cardinalidade, ou seja, muitos valores diferentes. Você até pode especificar várias colunas para ZORDER BY separando por vírgulas, mas a efetividade vai diminuindo conforme você adiciona mais colunas.
Shuffles e Partições: Como Evitar que os Dados Derramem

Image Source: LinkedIn
O shuffle no PySpark é daquelas coisas que podem destruir completamente o desempenho da sua aplicação. Sempre que você faz joins, agregações ou ordenações, o Spark precisa reorganizar os dados entre os nós do cluster. Quando isso não é feito direito, os dados começam a derramar para o disco, fazendo com que tudo fique lento.
spark.sql.shuffle.partitions: ajustando na mão conforme o volume de dados
O Spark vem configurado por padrão para usar 200 partições durante operações de shuffle. Esse número quase nunca é o ideal para o que você está fazendo. Se você usa poucas partições, cada tarefa vai processar muito dado e pode estourar a memória, causando aquele spilling chato para o disco. Do outro lado, se você usa muitas partições, acaba criando tarefas muito pequenas que gastam mais tempo com overhead do que processando dados.
Para ajustar isso:
spark.conf.set("spark.sql.shuffle.partitions", 50) # Exemplo para 5GB de dados num cluster de 10 coresExiste uma regra prática que funciona bem: cada tarefa deveria processar entre 128MB e 200MB de dados. Você pode calcular o número ideal de partições dividindo o volume total dos dados que vão passar pelo shuffle por esse valor. Outra opção é definir como 2 a 3 vezes o número total de núcleos de CPU que você tem disponível.
spark.sql.adaptive.autoOptimizeShuffle.preshufflePartitionSizeInBytes
O Databricks criou uma funcionalidade chamada Auto-Optimized Shuffle (AOS) que tenta descobrir automaticamente qual é o número ideal de partições:
spark.conf.set("spark.databricks.adaptive.autoOptimizeShuffle.enabled", "true")Todavia essa funcionalidade tem suas limitações. Quando você trabalha com tabelas que têm taxas de compressão excepcionalmente altas (20x a 40x), o AOS pode errar feio na estimativa do número de partições necessárias.
AQE para ajuste automático das partições de shuffle
O Adaptive Query Execution está habilitado por padrão desde o Apache Spark 3.2.0 e uma das coisas mais úteis que ele faz é ajustar dinamicamente o número de partições de shuffle.
Para configurar o AQE:
spark.conf.set("spark.sql.adaptive.enabled", "true")
spark.conf.set("spark.sql.adaptive.coalescePartitions.enabled", "true")
spark.conf.set("spark.sql.adaptive.advisoryPartitionSizeInBytes", "67108864") # 64MBO que acontece é que o AQE analisa o tamanho real dos dados depois do shuffle e ajusta o número de partições na hora. Imagine que você tem um DataFrame de 10GB com 200 partições originais – o AQE pode reduzir dinamicamente para 50 partições bem balanceadas durante a execução, melhorando o desempenho sem você precisar fazer nada.
O AQE também consegue dividir partições distorcidas em pedaços menores, evitando aqueles gargalos que fazem uma tarefa demorar muito mais que as outras e causam spilling. Isso é especialmente valioso quando você está trabalhando com dados que têm características imprevisíveis.
Identificar e Corrigir Skew e Explosão de Dados

Image Source: VLink Inc.
Uma das coisas mais chatas quando você está trabalhando com processamento distribuído é o tal do “skew” de dados. É aquela situação onde os dados ficam todos desbalanceados entre as partições do Spark, fazendo com que algumas tarefas tenham que processar muito mais dados que outras.
Você pode estar lá, achando que tudo está correndo bem, quando de repente uma tarefa demora uma eternidade para terminar enquanto as outras já acabaram há muito tempo.
Como descobrir skew usando o Spark UI
O Spark UI virou meu melhor amigo para caçar esses problemas. Quando você suspeita que tem skew, vai direto olhar:
- Na aba Stages, aquelas tarefas que demoram muito mais que a média
- As métricas de Summary Metrics onde você vê diferenças enormes entre os percentis
- Uma partição já é considerada problemática quando ela é maior que 5 vezes a mediana e passa de 256MB
A dica é ficar de olho nas métricas de “skewness” para identificar onde estão os gargalos. Quando a distribuição está saudável, os valores ficam parecidos em todos os percentis. Mas quando tem skew, você vê uma diferença brutal entre o 75º percentil e o valor máximo.
Resolver skew com hints e salting
Desde o Spark 3.0, o AQE consegue lidar automaticamente com joins que têm skew quando você coloca spark.sql.adaptive.enabled=true e spark.sql.adaptive.skewJoin.enabled=true.
Mas tem casos que ele não consegue resolver sozinho. Aí você precisa interferir:
- Usar skew hints explícitos para avisar o Spark sobre colunas problemáticas
- Aplicar a técnica do “salting” – que basicamente adiciona um pouco de aleatoriedade nas chaves:
df_salted = df.withColumn("salt", (rand() * 10).cast("int"))
df_salted = df_salted.withColumn("salted_key", col("key") + col("salt"))O salting funciona redistribuindo os dados de forma mais equilibrada, evitando que alguns recursos fiquem sobrecarregados.
Explode() e joins: os vilões da explosão de dados
Tem duas operações que são campeãs em fazer os dados explodirem:
- explode(): pega colunas que são coleções e transforma em linhas individuais, multiplicando o volume de dados
- joins: especialmente quando eles produzem muito mais linhas do que você esperava (dá para verificar isso no nó SortMergeJoin do Spark UI)
Já vi partições de 128MB virarem gigabytes por causa dessas explosões, e aí a memória disponível não aguenta.
Usar reparticionamento para controlar explosões
Quando você está lidando com explosões de dados, algumas estratégias podem salvar o dia:
- Diminuir o
spark.sql.files.maxPartitionBytesde 128MB para 16MB ou 32MB - Executar
repartition()logo depois de ler os dados - Para explosões que acontecem nos joins, aumentar o número de partições de shuffle
Essas técnicas conseguem evitar que os dados sejam jogados para o disco e melhoram muito o gerenciamento de memória quando você está processando volumes grandes.
Cache e Persistência: Como Ganhar Performance de Verdade
Usar cache é uma daquelas coisas que todo mundo fala que é importante, mas na prática muita gente não sabe direito quando e como usar. Acontece que armazenar dados em cache pode fazer uma diferença enorme no gerenciamento de memória do PySpark, especialmente quando você precisa reutilizar os mesmos dados várias vezes.
Delta Cache do Databricks: o cache que funciona sozinho
O cache de disco do Databricks, que antes chamavam de Delta Cache, é um recurso que acelera bastante a leitura de dados. Ele cria cópias locais dos seus arquivos Parquet usando um formato intermediário otimizado. O legal é que esse recurso já vem ativado automaticamente nos nós que têm volumes SSD, e ele usa no máximo metade do espaço disponível nesses dispositivos.
Para verificar se está funcionando ou mexer nas configurações:
# Ver como está configurado
spark.conf.get("spark.databricks.io.cache.enabled")
# Ligar ou desligar o cache
spark.conf.set("spark.databricks.io.cache.enabled", "true")Uma coisa interessante sobre esse cache de disco é que ele detecta automaticamente quando os arquivos mudam, então você não precisa ficar se preocupando em invalidar o cache manualmente. Isso é bem diferente do cache padrão do Apache Spark.
Como usar cache() e persist() sem quebrar tudo
Enquanto o Delta Cache cuida dos arquivos, o cache() e persist() são para melhorar o desempenho quando você vai usar o mesmo DataFrame várias vezes:
# Cache básico (usa MEMORY_AND_DISK por padrão)
df.cache()
# Persist com mais controle sobre onde guardar
df.persist(storageLevel=StorageLevel.MEMORY_ONLY)Aqui tem uma pegadinha importante: essas duas operações são operações de avaliação preguiçosa, ou seja, elas só vão executar quando você chamar uma ação. Se você quer que o cache aconteça na hora, precisa forçar:
df.persist()
df.count() # Isso força o cache a ser materializadoViews temporárias ou tabelas? Depende do que você quer
Views temporárias são virtuais, então toda vez que você acessa elas, a query roda de novo. Já as tabelas temporárias materializam os resultados. A escolha depende do seu caso:
- Views temporárias: quando é algo simples ou que você vai usar só uma vez
- Tabelas temporárias: para transformações pesadas que você vai acessar várias vezes
Existe uma estratégia interessante para operações que custam caro computacionalmente mas que você vai acessar com frequência. Você pode criar uma view temporária e depois fazer cache dela:
dataframe.createOrReplaceTempView("view_name")
spark.sql("CACHE TABLE view_name")Essa abordagem junta o melhor dos dois mundos: a flexibilidade das views com os benefícios de performance do cache.
Conclusão
Depois de passar por todas essas técnicas de gerenciamento de memória no PySpark, fica claro que não existe uma solução mágica que resolve tudo de uma vez. Cada problema tem suas particularidades e requer uma abordagem específica.
As ferramentas de análise de memória que chegaram com o Databricks Runtime 12.0 realmente mudaram o jogo. Antes era muito difícil entender onde estava o gargalo, agora conseguimos ver exatamente quais linhas de código estão consumindo mais recursos. Isso facilita muito nossa vida na hora de fazer as melhorias necessárias.
Vimos como o layout dos dados em tabelas Delta pode fazer uma diferença enorme na performance. O optimizeWrite e o autoCompact resolvem aquele problema chato dos pequenos arquivos, enquanto o ZORDER ajuda bastante quando você precisa consultar dados específicos com frequência.
A questão dos shuffles e partições continua sendo um dos pontos mais importantes para evitar que os dados sejam despejados no disco. O AQE ajuda bastante nisso, mas ainda precisamos entender nossos dados e ajustar as configurações quando necessário.
Aqui é importante destacar que problemas de skew e explosão de dados podem aparecer de formas inesperadas, especialmente quando você está trabalhando com volumes grandes. Saber identificar esses problemas no Spark UI e ter as técnicas de salting na manga faz toda a diferença.
As estratégias de cache, tanto o Delta Cache quanto o persist() nos DataFrames, completam esse conjunto de ferramentas. Quando usadas corretamente, eliminam muito reprocessamento desnecessário e economizam recursos.
Porém, todas essas técnicas hoje já fazem parte do cotidiano de quem trabalha com big data, e nós de alguma forma precisamos nos adaptar constantemente conforme nossos dados e workloads evoluem.
O importante é lembrar que otimização de memória não é algo que você faz uma vez e esquece. É um processo contínuo que precisa acompanhar o crescimento dos seus dados e a evolução das suas aplicações. Cada novo projeto traz seus próprios desafios, e ter essas ferramentas bem compreendidas facilita muito o trabalho de resolver os gargalos que aparecem pelo caminho.
Para quem quer se aprofundar mais nesse universo de processamento de dados em larga escala, vale a pena continuar estudando e praticando essas técnicas em cenários reais. A experiência prática é o que realmente consolida esse conhecimento.
FAQs
Q1. Como o Adaptive Query Execution (AQE) melhora o desempenho no PySpark? O AQE otimiza consultas durante a execução, ajustando dinamicamente o número de partições de shuffle e dividindo partições distorcidas. Isso resulta em melhor utilização de recursos e redução de gargalos de performance.
Q2. Quais são as melhores práticas para evitar o problema de “pequenos arquivos” no Delta Lake? Utilize recursos como optimizeWrite e autoCompact, ajuste o delta.targetFileSize e aplique ZORDER em colunas frequentemente filtradas. Essas técnicas otimizam o layout de dados, melhorando o desempenho das consultas.
Q3. Como identificar e corrigir problemas de skew de dados no Spark? Analise o Spark UI para identificar tarefas que demoram mais que a média e use métricas de shuffle. Para corrigir, utilize skew hints, implemente “salting” ou aproveite o AQE para gerenciar automaticamente joins distorcidos.
Q4. Qual a diferença entre o cache de disco do Databricks e o cache do Apache Spark? O cache de disco do Databricks (Delta Cache) otimiza a leitura de arquivos Parquet, detectando automaticamente alterações. Já o cache do Spark (cache() e persist()) melhora o desempenho de transformações repetidas em DataFrames.
Q5. Quando devo usar views temporárias em vez de tabelas intermediárias no Spark? Use views temporárias para consultas simples ou uso único, e tabelas temporárias para transformações complexas ou múltiplos acessos. Para operações custosas e frequentes, considere criar uma view temporária com cache para combinar flexibilidade e performance.
Referências
[1] – https://www.databricks.com/discover/pages/optimize-data-workloads-guide
[2] – https://www.databricks.com/blog/2022/11/30/memory-profiling-pyspark.html
[3] – https://blog.dataengineerthings.org/a-quick-guide-to-spark-and-databricks-optimization-engines-1d2089185cf2
[4] – https://learn.microsoft.com/en-us/azure/synapse-analytics/spark/optimize-write-for-apache-spark
[5] – https://delta.io/blog/delta-lake-optimize/
[6] – https://docs.databricks.com/aws/en/delta/tune-file-size
[7] – https://docs.databricks.com/aws/en/delta/data-skipping
[8] – https://community.databricks.com/t5/data-engineering/what-is-z-ordering-in-delta-and-what-are-some-best-practices-on/td-p/26639
[9] – https://www.databricks.com/blog/2020/10/21/faster-sql-adaptive-query-execution-in-databricks.html
[10] – https://www.sparkcodehub.com/pyspark/performance/shuffle-optimization
[11] – https://spark.apache.org/docs/3.5.0/sql-performance-tuning.html
[12] – https://www.databricks.com/notebooks/gallery/SparkAdaptiveQueryExecution.html
[13] – https://docs.aws.amazon.com/emr/latest/ReleaseGuide/emr-spark-performance.html
[14] – https://aws.amazon.com/blogs/big-data/detect-and-handle-data-skew-on-aws-glue/
[15] – https://www.linkedin.com/pulse/what-data-skewness-spark-how-handle-code-soutir-sen-xf6hf
[16] – https://docs.aws.amazon.com/prescriptive-guidance/latest/tuning-aws-glue-for-apache-spark/optimize-shuffles.html
[17] – https://spark.apache.org/docs/latest/sql-performance-tuning.html
[18] – https://spark.apache.org/docs/3.5.3/sql-performance-tuning.html
[19] – https://www.linkedin.com/pulse/handling-data-skewness-spark-power-salting-pyspark-kommanaboina-vskic
[20] – https://docs.databricks.com/aws/en/optimizations/disk-cache
[21] – https://learn.microsoft.com/pt-br/azure/databricks/optimizations/disk-cache
[22] – https://sparkbyexamples.com/pyspark/pyspark-cache-explained/
[23] – https://community.databricks.com/t5/data-engineering/temp-table-vs-temp-view-vs-temp-table-function-which-one-is/td-p/4087
[24] – https://www.chaosgenius.io/blog/databricks-temporary-table/
[25] – https://stackoverflow.com/questions/50716772/spark-tempview-performance
